Predicting the future based on knowledge of the past is fundamental. I always keep a keen eye on technological advances but never lose track of the past.
Past achievements and breakthroughs in the information retrieval (IR) field conjure the possibilities of “where to next” in search technology.
That then leads me to what impact it will have on search engine optimization (SEO) techniques and methodologies in the future.
In the previous installment of my SEO “Back to the Future” series, Indexing and keyword ranking techniques revisited: 20 years later, I concluded by showing a graphic that explains something known as the “abundance problem.” This frequently prevents pure keyword ranking techniques (on-page) from placing the more authoritative pages at the top of the results. Relevant – yes. But authoritative?
For Google quality raters, E-A-T may only have been around for a few years. But in the IR field, it has always been at the core of how and what search engines do.
In this article, I’ll explore how far back expertise, authoritativeness and trustworthiness (E-A-T) goes and what they’re actually based on.
‘E-A-T’ 20 years ago
There’s still quite a lot of ambiguity in the industry about what “authoritativeness” actually means in the SEO sense. How does a site/page become authoritative?
Perhaps looking at how “authority” – as well as the terms “expert” and “trust” – came into the IR and SEO lexicon can give you more insight.
Here’s a graphic I created back in 2002, but this version has a relevant enhancement to tie all this together.

I’ll use this classic web data mining graphic, now featuring the three letters E-A-T to help build a better understanding of its origins.
E-A-T in itself is not an algorithm, but:
- Expertise connects directly to page content.
- Authority connects directly to hyperlink analysis.
- Trust comes from a combination of page content and hyperlink analysis, plus end-user access data.
All three data mining aspects must be combined in a meta-search (or federated search) manner to provide the most authoritative pages to satisfy the end user’s information needs. Effectively, it’s a mutually reinforcing series of converged algorithmic ranking mechanisms.
As a long-time professional member of the Association for Computing Machinery, the world’s largest computing society, I’m proud to belong to the special interest group for information retrieval (SIGIR). My main area of focus within that group is hyperlink analysis and the science of search engine rankings.
For me, this is the most fascinating area of IR and SEO. As I’ve been heard to say at many conferences over the years: “Not all links are equal. Some are infinitely more equal than others.”
And that’s a good starting point for this next epic read for fellow SEO Bravehearts.
The evolution from text-based ranking techniques to hyperlink-based ranking algorithms
Let’s quickly cover the fundamental reason that links are essential to all search engines, not just to Google.
First, social network analysis has a distinguished history. The past two decades have seen a hugely developing interest and fascination in the scientific community on the idea of networks and network theory. As a basic overview, this simply means a pattern of interconnections among a set of things.
Social networks are not a new phenomenon by companies like Meta. Social ties among friends have been widely studied for many years. Economic networks, manufacturing networks, media networks, and so many more networks exist.
One experiment in the field that became very famous outside the scientific community is known as “Six Degrees of Separation,” which you may well be aware of.
The web is a network of networks. And in 1998, the hyperlink structure of the web became of great interest to a young scientist called Jon Kleinberg (now recognized as one of the world’s leading computer scientists) and to a couple of students from Stanford University, including Google Larry Page and Sergey Brin. During that year, the three produced two of the most influential hyperlink analysis ranking algorithms – HITS (or “Hyperlink-Induced Topic Search”) and PageRank.
To be clear, the web has no preference over one link or another. A link is a link.
But for those in the nascent SEO industry in 1998, that perspective would change completely when Page and Brin, in a paper they presented at a conference in Australia, made this statement:
“Intuitively, pages that are well cited from many places around the web are worth looking at.”
And then they gave an early clue endorsing the fact I highlighted that “not all links are equal” by following up with this:
“Also, pages that have perhaps only one citation from something like the Yahoo home page are also generally worth looking at.”
That last statement struck a real chord with me and, as a practitioner, has kept me focused on developing a more elegant approach to link attraction techniques and practices over the years.
In conclusion to this installment, I’m going to explain something about my approach (which has been hugely successful) that I feel will change, conceptually, the way you think about what is referred to as “link building” and change that to “reputation building.”
The origins of ‘authority’ in search
In the SEO community, the word “authority” is often used when talking about Google. But that’s not where the term originated (more on that later).
In the paper that the Google founders presented at the conference in Australia, it’s notable that although they were talking about a hyperlink analysis algorithm, they didn’t use the word “link” they used the word “citation.” This is because PageRank is based on citation analysis.
Loosely explained, that’s the analysis of the frequency, patterns, and graphs of citations in documents (a.k.a., links from one document to another). A typical aim would be to identify the most important documents in a collection.
The earliest example of citation analysis was the examination of networks of scientific papers to discover the most authoritative sources. Its overarching science is known as “bibliometrics” – which fits into the social network analysis and network theory category as I’ve already touched on.
Here’s how I transposed that 20 years ago in the absolute simplest way to show how Google viewed web linkage data.
“Some links on web pages are simply navigational aids to ‘browse’ a site. Other links may provide access to other pages which augment the content of the page containing them. Andrei Broder [Chief Scientist Alta Vista] pointed out that, a web page author is likely to create a link from one page to another because of its relevance or importance: “You know, what’s very interesting about the web is the hyperlink environment which carries a lot of information. It tells you: ‘I think this page is good’ – because most people usually list good resources. Very few people would say: ‘Those are the worst pages I’ve ever seen’ and put links to them on their own pages!
High quality pages with good, clear and concise information are more likely to have many links pointing to them. Whereas low quality pages will have fewer links or none at all. Hyperlink analysis can significantly improve the relevance of search results. All of the major search engines now employ some type of link analysis algorithms.”
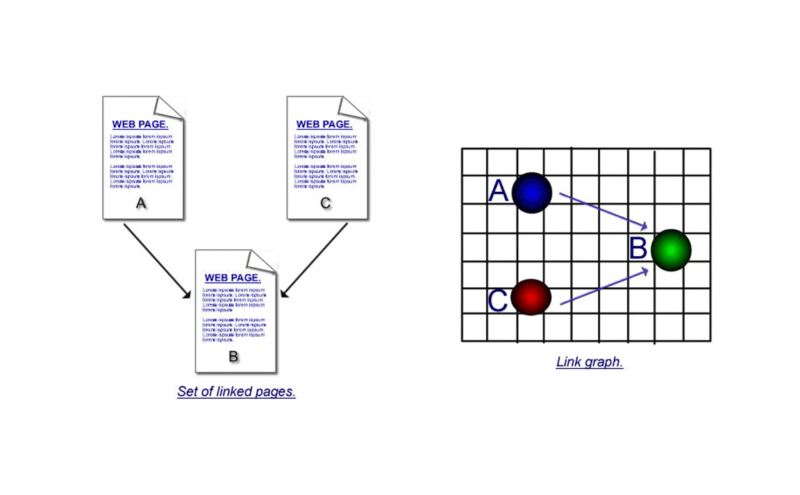
“Using the citation/co-citation principle as used in conventional bibliometrics, hyperlink analysis algorithms can make either one or both of these basic assumptions:
• A hyperlink from page ‘a’ to page ‘b’ is a recommendation of page ‘b’ by the author of page ‘a.’
• If page ‘a’ and page ‘b’ are connected by a hyperlink, then they may be on the same topic.
Hyperlink based algorithms also use an undirected co-citation graph. A and B are connected by an undirected edge, if and only if there is a third page C which links both to A and B.”
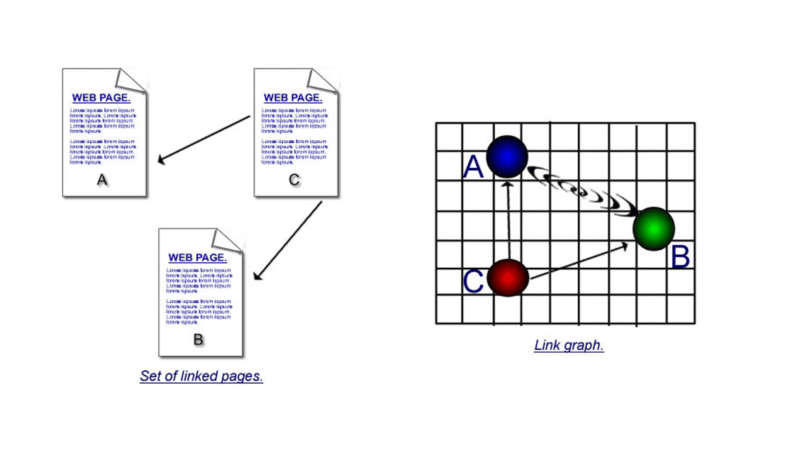
That second part had a much longer explanation to it in the book. But as it is a little confusing, I’ll give a really simplistic one here.
It’s important to understand the strengths of both citation and co-citation.
In the first illustration, there are direct links – one page using a hyperlink to connect to another. But if page ‘c’ links to ‘a’ and ‘b’ and then page ‘d’ links to ‘a’ and ‘b’ and then page ‘e’ and so on and so on, what you can assume is that, although page ‘a’ and page ‘b’ do not directly hyperlink to each other, because they are co-cited so many times, there must be some connection between them.
What would a real-life example of that be?
Well, lists to begin with. Pages with the “top ten” best-selling laptops, the “top ten” sports personalities, or rock stars, you can see how co-citation is a big factor in those types of pages.
So where does this HITS algorithm that you may never have heard of come into play?
There’s a story that at the same time Page and Brin were working on their PageRank algorithm, Kleinberg was analyzing results at the top search engines of the day, including the fastest growing among them, Alta Vista. He thought that they were all pretty poor and produced very meager results in terms of how relevant they were to the query.
He searched for the term “Japanese automotive manufacturer” and was very unimpressed to note that none of the major names such as Toyota and Nissan appeared anywhere in the results, let alone where they should be at the top.
After visiting the websites of the major manufacturers, he noticed one thing they all had in common: None of them had the words “Japanese automotive manufacturer” in the text on any site pages.
In fact, he searched for the term “search engine,” and even Alta Vista didn’t turn up in its own results for the very same reason. This caused him to start and focus on the connectivity of web pages to give a clue as to how relevant (and important) they were to a given query.
So, he developed the HITS algorithm, which took the top thousand or more pages following a keyword search at Alta Vista and then ranked them according to their interconnectivity.
Effectively, he was using the link structure to form a network or “community” around the keyword topic and, within that network, identify what he named “Hubs and Authorities.”
That’s where the word “authority” came into the SEO lexicon. The title of Kleinberg’s thesis was “Authoritative Sources in a Hyperlinked Environment.”
“Hub” pages are those with many links connecting to “authorities” on a given topic. The more hubs that link to a given authority, the more authority it gets. This is also mutually reinforcing. A good hub can also be a good authority and vice versa.
As usual, no prizes for my graphic-creating skills all those years ago, but this is how I visualized it back in 2002. Hubs (red) are those that link out to many “authorities” (blue) inside web communities.

So, what’s a “web community” then?
A web page data community refers to a set of web pages that has its own logical and semantic structures.
The web page community considers each web page as a whole object rather than breaking down the web page into information pieces and reveals mutual relationships among the concerned web data.
It is flexible in reflecting the web data nature, such as dynamics and heterogeneity. In the following graphic, each color represents a different community on the web.
I’ve always maintained that links attracted from within your own web community carry more prestige than those from outside your community.

I explained more about the importance of identifying communities this way 20 years ago:
“And as for linkage data: pages pointing (linking) to other pages can provide a massive amount of information about structure, communities, and hierarchy (largely referred to as the web’s “topology”). By using this methodology search engines can attempt to identify the intellectual structure (topology) and social networks (communities) of the web. However, there are many problems with scaling using methods of citation and co-citation analysis to deal with hundreds and hundreds of millions of documents with billions of citations (hyperlinks).
“Cyberspace” (as in the web) already has its communities and neighborhoods. OK – less real in the sense of where you live and who you hang out with. But there is a “sociology” to the web. Music lovers from diverse cultures and different backgrounds (and time zones) don’t live in the same geographical neighborhood – but when they are linked to each other on the web they’re very much community. Just the same as art lovers and people from every walk of life who post their information to the web and form these communities or “link neighborhoods” in “cyberspace.””
PageRank vs. HITS: What's the difference?
There are many similarities in both the PageRank and HITS algorithms in the way they analyze the interconnectivity of web pages to create a ranking mechanism.
But there's a significant difference as well.
PageRank is a keyword-independent ranking algorithm, while HITS is keyword-dependent.
With PageRank, you get your authority score regardless of the community as it was originally a static global score.
Whereas HITS is keyword-dependent, meaning the authority score is built around the keyword/phrase that pulls the community together. It takes too long and beyond the scope of this installment to go into detail, so I won't go too deeply here.
The algorithm that introduced the term 'expert'
This Hilltop algorithm is hugely important but gets the least attention. And that's because, in professional circles, there's a strong belief that it was merged into Google's algorithmic processes in 2003 when the infamous Florida update occurred.
A real game-changer, the Hilltop algorithm is a much closer derivative of HITS and was developed in 1999 (yes, all around the same time) by Krishna Bharat.
At the time, he was working for DEC Systems Research Center, which was the owner of the AltaVista search engine. His research paper was titled, "When Experts Agree: Using Non-Affiliated Experts to Rank Popular Topics." And this is how he described Hilltop.
"We propose a novel ranking scheme for popular topics that places the most authoritative pages on the query topic at the top of the ranking. Our algorithm operates on a special index of "expert documents." These are a subset of the pages on the WWW identified as directories of links to non-affiliated sources on specific topics. Results are ranked based on the match between the query and relevant descriptive text for hyperlinks on expert pages pointing to a given result page."
Yes, this is where the term "expert" came into the SEO lexicon. Notice both in the title of the paper and the description of the process your page is deemed to be an expert page when others link to it. So, the terms "expert" and "authority" can be used interchangeably.
One other thing that should be noted carefully – and that's the use of the term "non-affiliated" in the description of the algorithm. That may give a clue as to why many affiliate marketers were hit so badly with the Florida update.
Another that's important to note is that frequently in the SEO community, people refer to "authority sites" (or sometimes "domain authority" which is not even a thing). But the fact is, search engines return web pages in their results following a query, not websites.
The more links you attract from other "expert" pages, the more authority you gain, and the more "prestige" you can add to another expert page by linking to it. This is the beauty of building a "reputation" within the community – not simply being a link collector.
Whenever I explain the importance of being recognized as an expert within a web community, as I have for the last two decades, I know that sometimes people have difficulty visualizing what that would look like.
Fortunately, in my research work all those years ago, I came across another algorithm developed by two Japanese scientists, Masashi Toyoda and Kentarou Fukuchi. Their approach was the web community too, but they were able to output their results visually.
The example I took of theirs was one they used when they built a web community around computer manufacturers. Here's a small part of the output I lifted to use at conference sessions to help everyone get a more tangible idea of the notion.
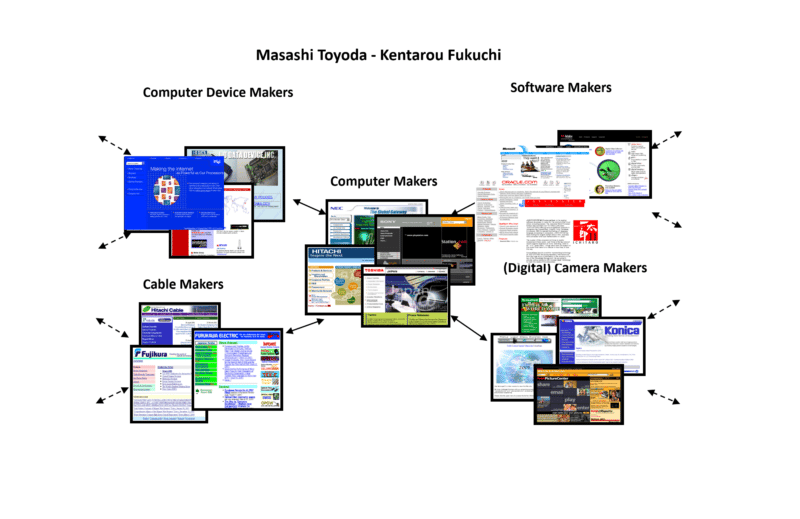
Notice how the web community includes not just computer manufacturers but also device makers, cable makers, software makers, etc. This indicates how broad and deep a web community can be (as well as narrow and shallow).
How 'trust' came to be
There's a lot that goes into "expertise" and "authoritativeness," and no less that goes into "trust."
Even "trust" falls into the area of hyperlink analysis and the structure of the web. A lot of work has gone into using the content and connectivity of "expert pages" that are trusted to discover and weed out spam. With AI and ML techniques, those connectivity patterns are much easier to spot and eliminate.
Back in the day there was an algorithm developed known as "TrustRank" and that's what it was based on. Of course, the acid test for "trust" really occurs with the end user.
Search engines endeavor to weed out spam and deliver results that truly satisfy users' information needs. So, user access patterns to pages provide a huge amount of data on which pages pass the web community test (connectivity) and then those that pass the end user test (user access data).
As I've mentioned, links from other web pages to your pages can be seen as a "vote" for your content. But what about the millions and millions of end users who don't have web pages to give you a link – how can they vote?
They do it with their "trust" by clicking on certain results – or not clicking on others.
It's all about whether end users are consuming your content – because if they're not – what's the point of Google returning it in the results following a query?
What 'expert', 'authority' and 'trust' mean in search
To summarize, you do not get to declare yourself an expert on your own pages.
You can "claim" to be an expert or an authority in a certain field or the world's leading this or that.
But philosophically, Google and other search engines are saying: "Who else thinks so?"
It's not what you say about yourself. It's what other people are saying about you (link anchor text). That's how you build a "reputation" in your community.
Moreover, Google's quality raters are not themselves determining whether your content is "expert" or you are an "authority" or not. Their job is to examine and determine whether Google's algorithms are doing their job.
This is such a fascinating subject and there's so much more to cover. But we're out of time and space for now.
Next time, I'll explain how important structured data is and being "semantically" connected within your web community is.
Until then, enjoy the golden colors of fall as we slide into another season with great anticipation for the next epic read on the inner workings of search engines.
The post The origins of E-A-T: Page content, hyperlink analysis and usage data appeared first on Search Engine Land.
from Search Engine Land https://ift.tt/gPWmFQt
via
No comments:
Post a Comment